Author

Arjan Neef
Testing, research and development
Scanning the internet
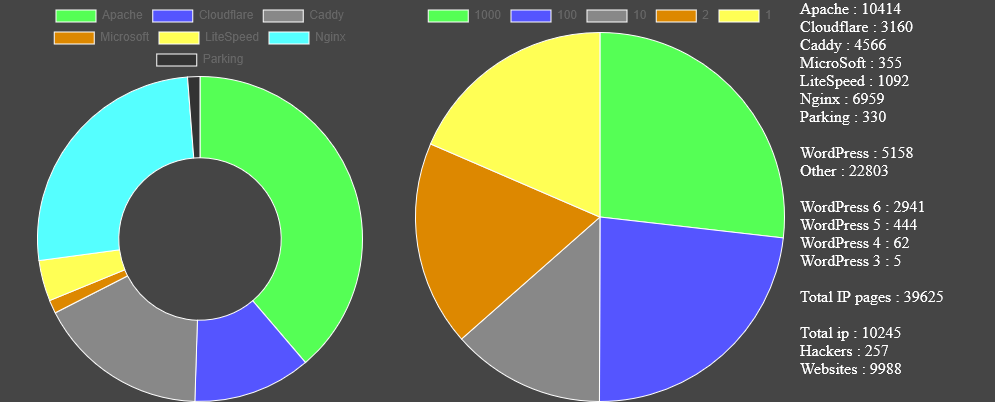
All information is out there. Out of curiosity I decided to setup a server that will collect free available information from websites by paying a visit to the website. For this I created a simple program that looks at the structure, technical information and building applications used to create the website. Just a data collector application to see what can be found. I was a bit surprised how much information can be collected without doing any hacking at all. Just basic stuff.
How to find websites?
Since I have no list available containing websites I decided to only scan for Dutch websites because I can use a dictionary to find a lot of websites. Just take a Dutch word, add https://www before it and .nl behind it and you have a possible link to a website. But not all words are actually used. To check this I added a small 'ping' command to get the IP address of this website. The ping may fail but it will tell me if the name is linked to an IP address. If so, this domain is used and the program can try to fetch the website information.
How to find a location?
Just like a city, IP addresses are linked to a location on earth. Since the program managed to get the IP address it can also request the GPS coordinates linked to this IP address. These can be plotted on a map. Now that I collected information about a webpage, its IP address and location this information can be very useful. With all this information the following interesting subjects are already collected.
- The name of a website
- The IP linked to this website
- Technical information about the hosting software
- Technical information about the used applications to build the website
- A location the website is hosted at
- The size of the hosting company the website belongs to
- If the size is equal to 1, this tell me that the actual website is hosted on a dedicated machine.
Identifying website hosting
If you look at the website name and the IP that is linked to the website you'll notice that more websites have the same IP address. This is because a hosting company links multiple domain names to the same IP address allowing it to host more than one company website on the same machine. But because my program matches a domain name to an IP these hosting companies are easily identified. In fact, it gives me a look into the hosting company and discover If this is a big or small hosting company.
Technical information
So what can you actually get from the technical information? Well, that depends on how well the website keeps this information hidden, but it also seems like most of the websites don't bother doing so. This allows me to collect the following information:
- The software used to host the website (Linux, Windows, Apache)
- Sometimes also the version of this software
- The software used to build the website (WordPress)
- Also, the version of this software
- The added plugins to the website, with version
Summary so far
As you have read, a lot of information can be collected from various different websites. Because a computer can automatically collect this information and there is nothing illegal about it you'll get a lot of information. With this information you can find weak spots on the internet, some weaker than others. But plotting this on the globe gives you a good insight.
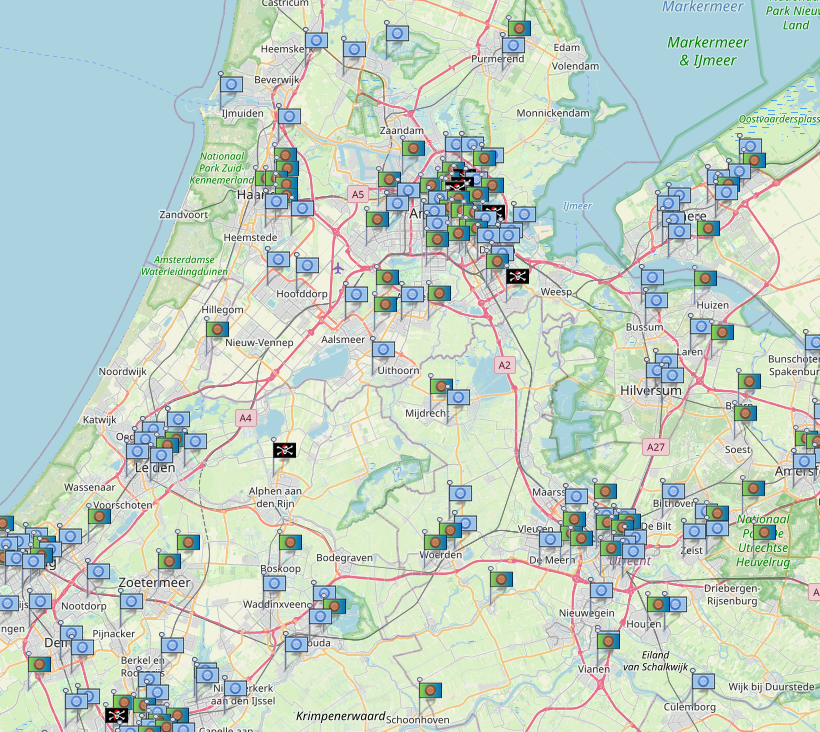
Identifying a hacked website
Now this is where the real fun starts. If you look at the image you'll notice a few pirate flags indicating the location of a possible hacker. These hackers have been identified by putting a decoy server online with only one task: Open a port and wait for a hacker to connect. I was surprised how many hack attempts were done so quickly. All my decoy does is log the IP address and compare this to the GPS locations and website IP's that have been gathered. If a location or IP is matched this means that either a hosting company is allowing one of it's users to do bad things or the actual website has been compromised. With this information I can actively try to get in touch with the one that should take action.
Manually collect information
A friend who knows about this program asked me to check a particular website to see how save this website actually is. It turned out to be the website of a school his child will go to. Sure, I'll have a look.
The basic information (all of the above) showed me the page is using an older version of WordPress and tries to hide most private information about the teachers. This makes sense as you might want to keep home and work separated. I also found a login portal for teachers they can use to login to their account. This also contained a 'I forgot my password' option. You need to provide a private email address or the real username for this to work. So I started to look for this information.
On the website there was some information containing the lastname of a teacher and what lectures he/she gives. A quick search on social media easily showed me the first and lastname of this person. So that information is already found. But digging in a little further on social media gave me more information. I was able to find home address, private phone numbers, private email addresses and the type of contract between teacher and school. (full-time/part time). Using this information allows me to either block the account of the teacher by resetting a password or possibly change it. I didn't want to do this but all information was there. So yeah, manually digging gives you even more useful information. Perhaps teachers need to learn about cybersecurity, privacy and social media?
Want me to help you scan your site, just let me know!